
目前互联网上有少量spider冒充Baiduspider抓取网页,Baiduspider ip的hostname以 *.baidu.com的格式命名,非 *.baidu.com即为冒充,那么如何查询确定抓却来源ip属于百度?使用DNS反查方式即可,具体操作如下:
1、辨别百度蜘蛛
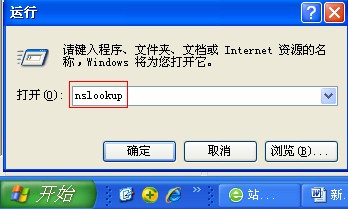
复制蜘蛛的IP,点击“开始”—“运行”—“CMD”—在光标闪的地方输入“nslookup”—回车键(如下图)
输入蜘蛛的IP再按回车(如下图)

返“Name:baiduspider-***-***-***-***.crawl.baidu.com”有这一行说明是百度的蜘蛛IP。否则为假蜘蛛。
百度电信:220.181.108.*等
百度联通123.125.71.*、123.125.67.*等
假蜘蛛:125.90.88.96(站长工具的假蜘蛛)
2、辨别谷歌蜘蛛
点击Windows系统里的“开始” – “运行”,输入tracert 203.208.60.179,点击确定。
运行结果显示:crawl-203-208-60-179.googlebot.com
但我发现现在的采集越来越高明,也会伪造反向DNS来指向***.googlebot.com。这时候,我们需要验证运行结果的反向DNS得出的IP地址。
点击Windows系统里的“开始”–“运行”,输入tracert crawl-203-208-60-179.googlebot.com,点击确定。
运行结果得出的IP地址与原本检测IP对应即可。
以上就是笔者总结出通过通过网站日志如何辨别蜘蛛的真假的方法,希望对大家有所帮助,如果大家有更好的方法也欢迎交流和探讨。
 鲁公网安备 37021402001407号
鲁公网安备 37021402001407号